14 Apr 2010
These are basically some notes for me because I just had to relearn all of it.
To use OpenCmsTestCase in a project the following steps have to be applied:
- Download the source distribution and unzip it
- set the file encoding: export ANT_OPTS=-Dfile.encoding=iso-8859-1
- run ant bindist
- run ant compile-tests
- Somehow some unittests are always not compiling for me: remove the java files and the entries from the TestSuites
- create a jar file from the folder org in ../BuildCms/build/test, e.g. jar -cf opencms-test-7.5.2.jar org
- add the jar to your project classpath/deploy to your maven repository
- add hsqldb.jar to your project
- copy the folders data and webapp to your project
- copy test/log4j.properties and test/test.properties to your test classpath and adjust the directory paths in test.properties (a good reason to use Maven so you can use the resource filtering mechanism)
- play with the files in data/imports and adjust them to your needs
A simple test case example:
import org.opencms.file.CmsObject;
import org.opencms.file.CmsResource;
import org.opencms.test.OpenCmsTestCase;
import org.opencms.test.OpenCmsTestProperties;
public class DummyOpenCmsTest extends OpenCmsTestCase {
static {
OpenCmsTestProperties.initialize(OpenCmsTestProperties.getResourcePathFromClassloader("test.properties"));
}
public DummyOpenCmsTest(String name) {
super(name);
}
@Override
public void setUp() throws Exception {
super.setUp();
setupOpenCms("simpletest", "/sites/default/");
}
public void testExistingResource() throws Exception {
CmsObject cms = getCmsObject();
CmsResource res = cms.readResource("/index.html");
assertEquals("/sites/default/index.html", res.getRootPath());
}
@Override
public void tearDown() throws Exception {
super.tearDown();
removeOpenCms();
}
}
Read more
10 Apr 2010
Problems with encoding are common on a lot of projects I worked on. Sometimes I tend to get the feeling that I understand most of it but then there are always aspects I did not get right. This week I noticed that even my basic knowledge is not really firm.
Currently I am working on a system where we do a lot of imports from other systems that provide data as XML. The company that delivers the data sent us some sample data that we tried to import. The XML document was supposed to be in
UTF-8 but somehow our parser always choked on some byte sequences. When we added iso-8859-1 to the xml prolog the parsing was working fine but all non-ASCII characters where not displayed correctly.
Using hexedit I looked at the document and located the values for non-ASCII characters like 'ä' which is displayed as 'C3 A4' in hex. But looking it up in the
Unicode code chart it should be the value '00 E4'. We complained that the data seemed to be send in a different encoding but not UTF-8.
Of course the company could not find any problem because we were just wrong. Unicode is not UTF-8! UTF-8 is an encoding scheme which is used to encode unicode characters but the byte values do not match.
Let's analyze the example character 'ä' in a UTF-8 document. It displays as 'C3 A4'. In binary format this is:
1100 0011 1010 0100
UTF-8 uses a start byte and one or more continuation bytes. A start byte is identified by two leading '11' which makes the first byte our start byte. Continuation bytes are identified by a leading '10', so the second byte is a continuation byte. These are the control bits that are used by UTF-8. Let's see what our sequence looks like if we just remove these control bits, shift the bits together and pad the left side with 0:
0000 0000 1110 0100
Of course this is the expected Unicode value '00 E4' for 'ä'.
Very basic, but I still managed to get it wrong.
Later a colleague noticed that in some part of our application a String was created from a byte array without specifying an explicit encoding. Ouch! Finally it was fixed quickly but we should have looked at our code first before blaming the data provider.
Read more
09 Apr 2010
As I am the one who does most of our
OpenCms projects I am also the one who has to deploy new versions to our internal
Nexus repository so we can easily use the libraries from
Maven.
The guys developing OpenCms use Ant for their builds so there is no official Maven repository available.
Most of the time I added only the dependencies that are really necessary on compile time because creating a Maven POM by hand is quite cumbersome, not to mention the deployment of all the dependencies (either uploading to Nexus or deploying using Maven). One of those time consuming tasks that needs some automation.
I chose
Groovy for implementing a little helper script because it is really good at dealing with XML and it's always good to learn some new techniques. I already got some experience in modifying existing scripts but did not use it for creating something from scratch.
The script basically just reads a folder with jars and creates a pom for the whole project as well as a script for deploying all additional artifacts using Maven. Creating the files currently involves two steps:
- A properties file is created from the information that is guessed from the filename of the jars. As jars are often not named consistent this will not succeed for all jars. So you have to review the file and change some group names, artifactIds and versions (another step that could be automated, e.g. by querying a Nexus instance, but let's save some work for the future ;) ). Another properties file holds project and deployment information like project groupId and artifactId and the server to deploy to.
- The properties files are read again by another script and the project pom as well as the deployment script is generated.
Of course you also have to review the deployment script because you don't want to deploy any artifacts that are already available. A good way to find out which artifacts are missing is to call something like {{{mvn compile}}} on the generated pom.
I uploaded the
(uncommented) scripts and helper classes, maybe it's useful for somebody.
I guess there are far better solutions to creating maven projects from existing libraries, I am looking forward to hearing about them.
The XML manipulation features of Groovy are really nice. When writing XML you append your node structure to a builder object and it creates the markup for you. You always stay very close to the format you intend to output. E.g. this is the code to create the XML for a pom file:
def writer = new StringWriter();
def xmlBuilder = new MarkupBuilder(writer);
xmlBuilder.project('xmlns' : 'http://maven.apache.org/POM/4.0.0',
'xmlns:xsi' : 'http://www.w3.org/2001/XMLSchema-instance',
'xsi:schemaLocation' : 'http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd') {
modelVersion('4.0.0')
groupId(project.group)
artifactId(project.artifact)
packaging('jar')
version(project.version)
name(project.artifact)
dependencies() {
dependencies.each() { dep ->
dependency {
groupId(dep.group)
artifactId(dep.artifact)
version(dep.version)
}
}
}
}
You are looking at this code and immediately can imagine the structure of the resulting XML. I like it!
Also, file manipulation is really nice. No need to do any resource cleanup. This code is responsible for writing the created pom file:
new File(dir + "pom.xml").withWriter() { out ->
out.println(projectPom.toString());
}
Some drawbacks I noticed when doing scripting like this:
- I tend to get sloppy while coding. Not adding semicolons to the end of lines, doing too many things in one class/script, ...
- Code completion in Netbeans is horrible if you are used to Java standards, but I guess that is just very hard to implement
- You have to compile manually, at least in Netbeans. If you are changing a Groovy class that is used by a script you have to remember to do a build because when running the script Netbeans will not compile it for you.
- A lot of coding errors are only discovered on runtime. E.g. using the wrong name for properties or calling a constructor that doesn't exist
I still can't imagine using a dynamic language on production code. Of course the deployment time tends to be shorter but still you have to execute the code to see if it is really correct. I doubt that writing tests could compensate for the lack of static type checking but probably this needs a shift of the mindset.
Read more
15 Mar 2010
TreeMap is the only implementation of a
SortedMap that is included in the JDK. It stores its values in a
Red-black tree, therefore its entries can be accessed, inserted and deleted really fast.
Unfortunately, using the class is not really intuitive, so you better read the API docs carefully or prepare to spend hours of your time chasing mysterious bugs.
Imagine that you want to use a TreeMap with String keys and String values that is ordered according to the length of the key in a way so that the longest key comes first. Should be quite simple, just implement a comparator that does the work for you:
import java.util.Comparator;
public class StringLengthComparator implements Comparator<String> {
public int compare(String o1, String o2) {
// if both lengths are the same return 0
return o2.length() - o1.length();
}
}
If both Strings have the same length we return 0 and a negative or positive value otherwise. As I always get confused when to return a positive value and when a negative let's create a simple test:
Map<String, String> map;
@Before
public void setUp() {
map = new TreeMap<String, String>(new StringLengthComparator());
}
@Test
public void testValuesWithDifferentLength() {
map.put("zero", "0");
map.put("one", "1");
map.put("three", "3");
assertThat("Length failed", map.size(), is(3));
Iterator<String> it = map.keySet().iterator();
assertThat(it.next(), is("three"));
assertThat(it.next(), is("zero"));
assertThat(it.next(), is("one"));
}
If we run this test everything seems to be ok;
Testsuite: StringLengthComparatorTest
Tests run: 1, Failures: 0, Errors: 0, Time elapsed: 0,018 sec
But what happens if we just insert the missing two? Lets see:
@Test
public void testDifferentValuesWithSameLength() {
map.put("zero", "0");
map.put("one", "1");
map.put("two", "2");
map.put("three", "3");
assertThat("Length failed", map.size(), is(4));
Iterator<String> it = map.keySet().iterator();
// just check the first two values as we do not know the order of the same length
assertThat(it.next(), is("three"));
assertThat(it.next(), is("zero"));
}
This test should also pass, we just can't tell the ordering of the same length keys:
Testcase: testDifferentValuesWithSameLength(StringLengthComparatorTest): FAILED
Length failed
Expected: is <4>
got: <3>
Oops ... what happened here? One of the values just disappeared? We are inserting 4 entries but there are only 3 in the Map?
The first time I stumbled across this it took me several hours to figure out what was going on. After I found out what the problem was it should have taught me to always read the javadoc carefully. The contract for TreeMap states the following:
Note that the ordering maintained by a sorted map (whether or not an explicit comparator is provided) must be consistent with equals if this sorted map is to correctly implement the Map interface.
What exactly does this mean?
Comparator tells us more about consistent with equals:
The ordering imposed by a comparator c on a set of elements S is said to be consistent with equals if and only if c.compare(e1, e2)==0 has the same boolean value as e1.equals(e2) for every e1 and e2 in S.
Normally, the Map- and Set-Interface use equals to determine if a certain key (for a Map) or a certain value (for a Set) is already inserted. But for TreeMap and TreeSet this is not the case. These implementations use compareTo for determining whether an Object is equal to another Object. This means you are not allowed to return 0 from a compare-method if the two Objects are not equal!
How to fix it? Just test if the two Strings are equal before comparing the length in the Comparator:
public int compare(String o1, String o2) {
// return 0 only if both are equal
if (o1.equals(o2)) {
return 0;
} else if (o1.length() > o2.length()) {
return -1;
} else {
return 1;
}
}
Alright, the test passes. Just to be sure we add another test:
@Test
public void testYetMoreValues() {
map.put("zero", "0");
map.put("one", "1");
map.put("four", "4");
assertThat("Length failed", map.size(), is(3));
assertNotNull("Zero's not there", map.get("zero"));
}
Seems to be a stupid test but let's see what happens:
Testsuite: StringLengthComparatorTest
Tests run: 3, Failures: 1, Errors: 0, Time elapsed: 0,027 sec
Testcase: testYetMoreValues(StringLengthComparatorTest): FAILED
Zero's not there
junit.framework.AssertionFailedError: Zero's not there
at StringLengthComparatorTest.testYetMoreValues(StringLengthComparatorTest.java:51)
How can this happen? We tested for equality but the "zero" value still is not there? Let's see what the tree looks like on every step.
Still simple if the first value ("zero") is inserted: The entry is the root node:

When inserting "one" afterwards, the Comparator tells that the result of the comparison is 1, which means that the node has to be inserted on the right side:
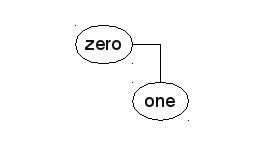
When inserting "four", the tree looks a little bit different. As our Comparator in this case also return 1, the node is also inserted right of "zero" but needs to be left of "one". "four" is our new root node:
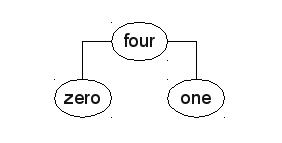
Seems to look ok. When reading from left to right the nodes are sorted according to their length. But let's see what happens when we try to look up "zero" based on the tree above. We start with the root node "four". As the length of "zero" and "four" is the same, our Comparator returns 1. But on the right side it only finds the "one" node. Our comparator returns -1 when comparing "four" to "one". Nothing there, so null is returned.
The Javadoc for Comparator tells us more on what went wrong here:
The implementor must ensure that sgn(compare(x, y)) == -sgn(compare(y, x)) for all x and y.
This means that the method needs to be implemented symetrically. When calling compare("zero", "one") we always need to return the negated value of calling compare("one", "zero"). With our implementation this is not the case as we always return 1 as a fallback.
I hope this is a final implementation of the Comparator delegating to Strings compareTo()-method which is already implemented symetrically:
public int compare(String o1, String o2) {
// return 0 only if both are equal
if (o1.equals(o2)) {
return 0;
} else if (o1.length() == o2.length()) {
// delegate to Strings compareTo to get symmetric behavior
return o1.compareTo(o2);
} else if (o1.length() > o2.length()) {
return -1;
} else {
return 1;
}
}
I struggled with both of these problems on two different projects and it always took me some hours. Thanks to my colleague Marc who led me to the solution of the symmetric problem.
Read more
19 Nov 2009
I am using
OpenCms, the open source content management system, quite often. It is a good choice for building structured medium to large sized websites. One drawback though sometimes is the layout of the APIs. E.g. for accessing the resources managed in the system programatically you have to use some final and nonfinal classes that depend on a running instance of OpenCms. The original developers very likely chose this approach for security reasons but this can become quite cumbersome, e.g. when dealing with tests, as you cannot mock some of these classes easily. There is an integration test facility that comes with OpenCms but as this starts an OpenCms instance every time a test is executed, running tests takes some time. I tend to write tests that work without a running system whenever possible.
To improve testability of my components I implemented a thin layer above the normal OpenCms access means using some interfaces and simple POJOs so that my business logic can be tested without starting OpenCms. One interface and its default implementation act as a kind of DAO for accessing the virtual filesystem of OpenCms. Its method signatures do not contain any OpenCms dependencies that can't be mocked or reconstructed easily. E.g. to represent file resources the OpenCms class normally used is
CmsResource. This class is quite difficult to instanciate outside of a running OpenCms instance as it contains internal references to different database tables. To reduce the need for mocking these external classes I implemented a simple POJO,
Resource, that contains relevant information like the path to the resource and it's type.
Some methods of my VFS DAO return a
Collection of
Resources, e.g. when reading all resources in a subfolder. As the OpenCms API returns an untyped
List that contains
CmsResources and in my interface method signature I use
List<? extends Resource> some transformation needs to take place. In the first project I used the abstraction I implemented it in a really simple way:
List<Resource> resources = new ArrayList<Resource>();
@SupressWarnings("Unchecked")
List<CmsResources> cmsResources = cms.readResources(...);
for (CmsResource cmsResource: cmsResources) {
resources.add(transform(cmsResource);
}
The transform method just creates an instance of the
Resource and fills it with the needed values.
private Resource transform(CmsResource cmsResource) {
Resource resource = new Resource();
resource.setDateLastModified(cmsResource.getDateLastModified());
...
return resource;
}
This approach works and in my opinion is ok to use in many circumstances. I sacrificed some performance for a gain in testability and design. But for large collections or operations that are triggered frequently this of course can become a performance issue as for the sake of abstraction it is necessary to iterate the collection.
The better solution is to use a lazy list that transforms the
CmsResources on the fly to
Resources. With a lazy list you don't have to iterate it when transforming. The transformation happens when you are accessing the list.
Google Collections provides a functional style approach for transforming lists lazily. You create a class that implements the interface
Function that can be typed for the source and target. In its
apply method the transformation step is implemented in basically the same way as in the method displayed above.
public class ResourceTransformationFunction implements Function {
public Resource apply(CmsResource cmsResource) {
Resource resource = new Resource();
resource.setDateCreated(cmsResource.getDateCreated());
resource.setDateLastModified(cmsResource.getDateLastModified());
...
return resource;
}
}
The original
List is transfomed using a static method call that accepts an instance of our
Function:
@SuppressWarnings("unchecked")
List<CmsResource> cmsResources = cms.readResources(...);
List<Resource> resources = Lists.transform(cmsResources, new ResourceTransformationFunction());
The transformation happens when the
List is accessed so when you are iterating the collection only once, which should be the case in most applications, there is no overhead at all (besides the creation of the new objects).
I really like the ease of use and reusabilty of the Google Collections solution. Also, the jar comes with absolutely no dependencies which makes it easily embedabble in any project.
A similiar functional approach will be part of the new concurrency features in JDK 7.
ParallelArray, which makes use of the Fork/Join framework will provide the ability to use functions and predicates when constructing arrays. Brian Goetz'
talk on Devoxx 2008 contained a detailed introduction to these features.
On Devoxx 2009, Dick Wall of the
Javaposse held a really good talk about appliying a more functional style of programming to the Java programming language. This talk will be available some time in the future at
parleys.com
Read more



