
Java Clients for Elasticsearch Transcript
09 Nov 2016This is a transcript of a talk I gave at the Singapore Java User Group on November 9 2016. It can also be seen as an updated version of an article with the same name I published in 2014 on the Found blog.
In this talk I will introduce three different clients for elasticsearch as well as Spring Data Elasticsearch. But to get started let's look at some of the basics of elasticsearch.
elasticsearch
To introduce elasticsearch I am using a definition that is taken directly from the elastic website.
Elasticsearch is a distributed, JSON-based search and analytics engine, designed for horizontal scalability, maximum reliability, and easy management.
Let's see first what a JSON-based search and analytics engine means.
To understand what elasticsearch does it's good to see an example of a search page. This is something everybody is familiar with, the code search on Github.
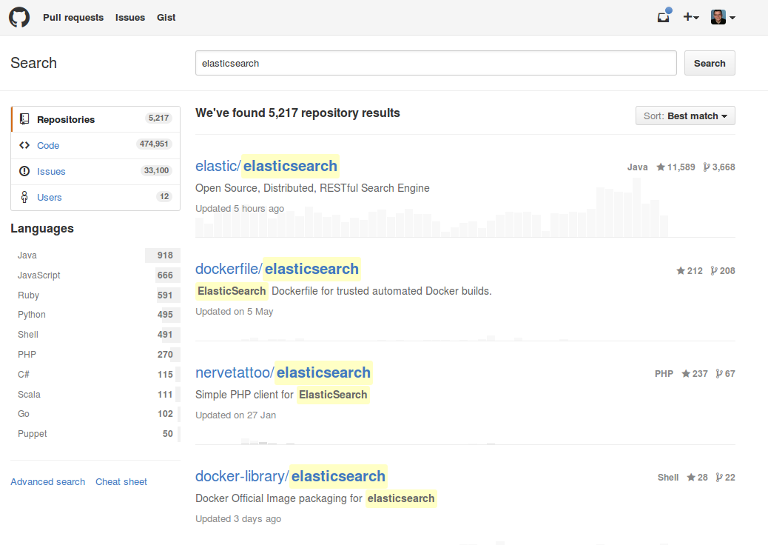
Keywords can be entered in a single search input, below is a list of results. One of the distinguishing features between a search engine and other databases is that there is a notion of relevance. We can see that for our search term elasticsearch the project for the search engine is on the first place. It's very likely that people are looking for the project when searching for this term. The factors that are used to determine if a result is more relevant than another can vary from application to application - I don't know what Github is doing but I can imagine that they are using factors like popularity besides classical text relevance features. There are a lot more features on the website that a classical search engine like elasitcsearch supports: Highlighting the occurance in the result, paginate the list and sort using different criteria. On the left you can see the so called facets that can be used to further refine the result list using criteria from the documents found. This is similar to features found on ecommerce sites like ebay and Amazon. For doing something like this there is the aggregation feature in elasticsearch that is also the basis for its analytics capabilities. This and a lot more can be done using elasticsearch as well. In this case this is even more obvious - Github is actually using elasticsearch for searching through the large amount of data they are storing.
If you want to build a search application like this you have to install the engine first. Fortunately elasticsearch is really easy to get started with. There is no special requirement besides a recent Java runtime. You can download the elasticsearch archive from the elastic website, unpack it and start elasticsearch using a script.
# download archive
wget https://artifacts.elastic.co/downloads/
elasticsearch/elasticsearch-5.0.0.zip
unzip elasticsearch-5.0.0.zip
# on windows: elasticsearch.bat
elasticsearch-5.0.0/bin/elasticsearch
For production use there are also packages for different Linux distributions. You can see that elasticsearch is started by doing a HTTP GET request on the standard port. In the examples I am using curl, the command line client for doing HTTP requests, that is available for a lot of environments.
curl -XGET "http://localhost:9200"
elasticsearch will answer this request with a JSON document that contains some information on the installation.
{
"name" : "LI8ZN-t",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "UvbMAoJ8TieUqugCGw7Xrw",
"version" : {
"number" : "5.0.0",
"build_hash" : "253032b",
"build_date" : "2016-10-26T04:37:51.531Z",
"build_snapshot" : false,
"lucene_version" : "6.2.0"
},
"tagline" : "You Know, for Search"
}
The most important fact for us is that we can see that the server is started. But there is also versioning information on elasticsearch and Lucene, the underlying library used for most of the search functionality.
If we now want to store data in elasticsearch we send it as a JSON document as well, this time using a POST request. As I really like the food in Singapore I want to build an application that allows me to search my favorite food. Let's index the first dish.
curl -XPOST "http://localhost:9200/food/dish" -d'
{
"food": "Hainanese Chicken Rice",
"tags": ["chicken", "rice"],
"favorite": {
"location": "Tian Tian",
"price": 5.00
}
}'
We are using the same port we used before, this time we just add two more fragments to the url: food and dish. The first is the name of the index, a logical collection of documents. The second is the type. It determines the structure of the document we are saving, the so called mapping.
The dish itself is modeled as a document. elasticsearch supports different data types like string, that is used for the food attribute, a list like in tags and even embedded documents like the favorite document. Besides that there are more primitive types like numerics, booleans and specialized types like geo coordinates.
We can now index another document doing another POST request.
curl -XPOST "http://localhost:9200/food/dish" -d'
{
"food": "Ayam Penyet",
"tags": ["chicken", "indonesian"],
"spicy": true
}'
The structure of this document is a bit different. It doesn't contain thefavorite subdocument but has another attribute spicy instead. Documents of the same kind can be very different - but keep in mind that you need to interpret some parts in your application. Normally you will have similar documents.
With those documents indexed it is automatically possible to search them. One option is to do a GET request on /_search and add the query term as a parameter.
curl -XGET "http://localhost:9200/food/dish/_search?q=chicken"
Searching for chicken in both documents also returns both of them. This is an excerpt of the result.
...
{"total":2,"max_score":0.3666863,"hits":[{"_index":"food","_type":"dish","_id":"AVg9cMwARrBlrY9tYBqX","_score":0.3666863,"_source":
{
"food": "Hainanese Chicken Rice",
"tags": ["chicken", "rice"],
"favorite": {
"location": "Tian Tian",
"price": 5.00
}
}},
...
There is some global information like the amount of documents found. But the most important property is the hits array that contains the original source of our indexed dishes.
It's very easy to get started like this but most of the time the queries will be more complex. That's why elasticsearch provides the query DSL, a JSON structure that describes a query as well as any other search features that are requested.
curl -XPOST "http://localhost:9200/food/dish/_search" -d'
{
"query": {
"bool": {
"must": {
"match": {
"_all": "rice"
}
},
"filter": {
"term": {
"tags.keyword": "chicken"
}
}
}
}
}'
We are searching for all documents that contain the term rice and also have chicken in tags. Accessing a field using the .keyword allows to do an exact search and is a new feature in elasticsearch 5.0.
Besides the search itself you can use the query DSL to request more information from elasticsearch, be it something like highlighting or autocompletion or the aggregations that can be used to build a faceting feature.
Let's move on to another part of the definition.
Elasticsearch is [...] distributed [...], designed for horizontal scalability, maximum reliability
So far we have only accessed a single elasticsearch instance.
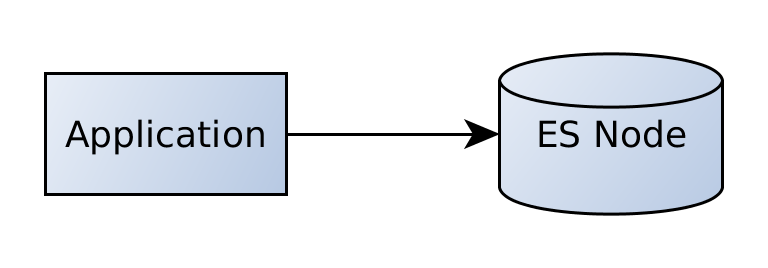
Our application would be talking directly to that node. Now, as elasticsearch is designed for horizontal scalability we can also add more nodes.
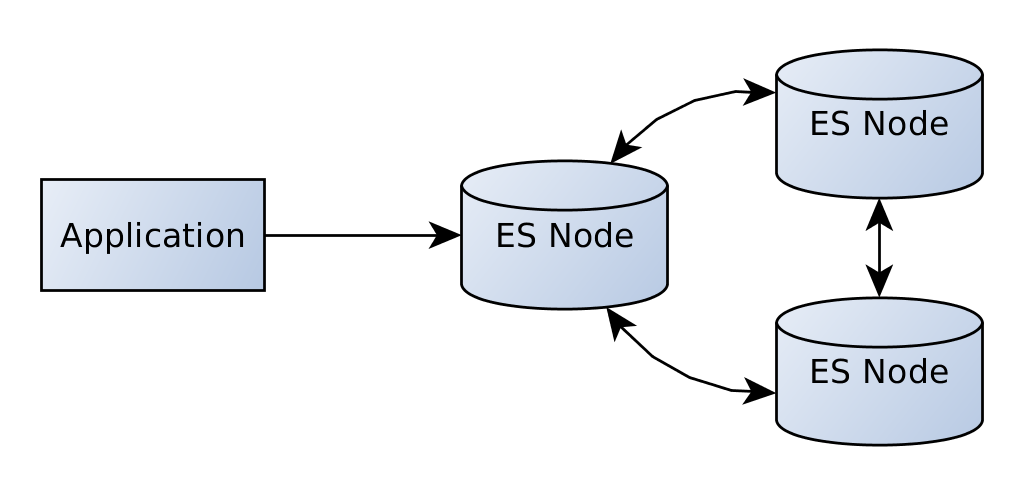
The nodes form a cluster. We can still talk to the first node and it will distribute all requests to the necessary nodes of the cluster. This is completely transparent to us.
Building a cluster with elasticsearch is really easy at the beginning but of course it can be more challenging to maintain a production cluster.
Now that we have a basic understanding about what elasticsearch does let's see how we can access it from a Java application.
Transport Client
The transport client has been available from the beginning and is the client chosen most frequently. Starting with elasticsearch 5.0 it has its own artifact that can be integrated in your build, e.g. using Gradle.
dependencies {
compile group: 'org.elasticsearch.client',
name: 'transport',
version: '5.0.0'
}
All functionality of Elasticsearch is available using the Client interface, a concrete instance is the TransportClient, that can be instanciated using a Settings object and can have one or more addresses of elasticsearch nodes.
TransportAddress address =
new InetSocketTransportAddress(
InetAddress.getByName("localhost"), 9300);
Client client = new PreBuiltTransportClient(Settings.EMPTY)
addTransportAddress(address);
The client then provides methods for different features of elasticsearch. First, let's search again. Recall the structure of the query we issued above.
curl -XPOST "http://localhost:9200/food/dish/_search" -d'
{
"query": {
"bool": {
"must": {
"match": {
"_all": "rice"
}
},
"filter": {
"term": {
"tags.keyword": "chicken"
}
}
}
}
}'
A bool query that has a match query in its must section and a term query in its filter section.
Luckily once you have a query like this you can easily transform it to the Java equivalent.
SearchResponse searchResponse = client
.prepareSearch("food")
.setQuery(
boolQuery().
must(matchQuery("_all", "rice")).
filter(termQuery("tags.keyword", "chicken")))
.execute().actionGet();
assertEquals(1, searchResponse.getHits().getTotalHits());
SearchHit hit = searchResponse.getHits().getAt(0);
String food = hit.getSource().get("food").toString();
We are requesting a SearchSourceBuilder by calling prepareSearch on the client. There we can set a query using the static helper methods. And again, it's a bool query that has a match query in its must section and a term query in its filter section.
Calling execute returns a Future object, actionGet is the blocking part of the call. The SearchResponse represents the same JSON structure we can see when doing a search using the HTTP interface. The source of the dish is then available as a map.
When indexing data there are different options available. One is to use the jsonBuilder to create a JSON representation.
XContentBuilder builder = jsonBuilder()
.startObject()
.field("food", "Roti Prata")
.array("tags", new String [] {"curry"})
.startObject("favorite")
.field("location", "Tiong Bahru")
.field("price", 2.00)
.endObject()
.endObject();
It provides different methods that can be used to create the structure of the JSON document. This can then be used as the source for an IndexRequest.
IndexResponse resp = client.prepareIndex("food","dish")
.setSource(builder)
.execute()
.actionGet();
Besides using the jsonBuilder there are several other options available.
A common option is to use a Map, the convenience methods that accept field name and value for simple structures or the option to pass in a String, often in combination with a library like Jackson for serialization.
We have seen above that the Transport Client accepts the address of one or more elasticsearch nodes. You might have noticed that the port is different to the one used for http, 9300 instead of 9200. This is because the client doesn't communicate via http - it connects to an existing cluster using the transport protocol, a binary protocol that is also used for inter node communication in a cluster.
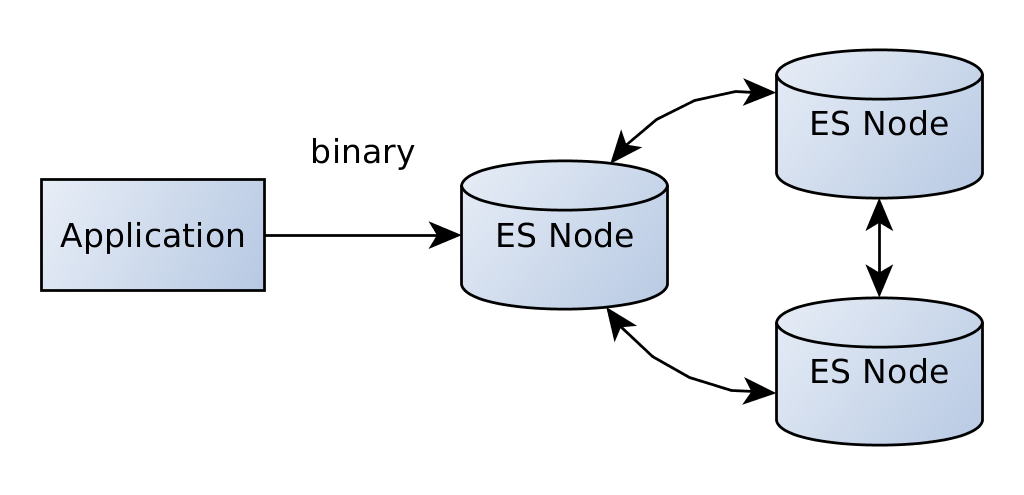
You might have noticed as well that so far we are only talking to one node of the cluster. Once this node goes down we might not be able to access our data anymore. If you need high availability you can enable the sniffing option that lets your client talk to multiple nodes in the cluster.
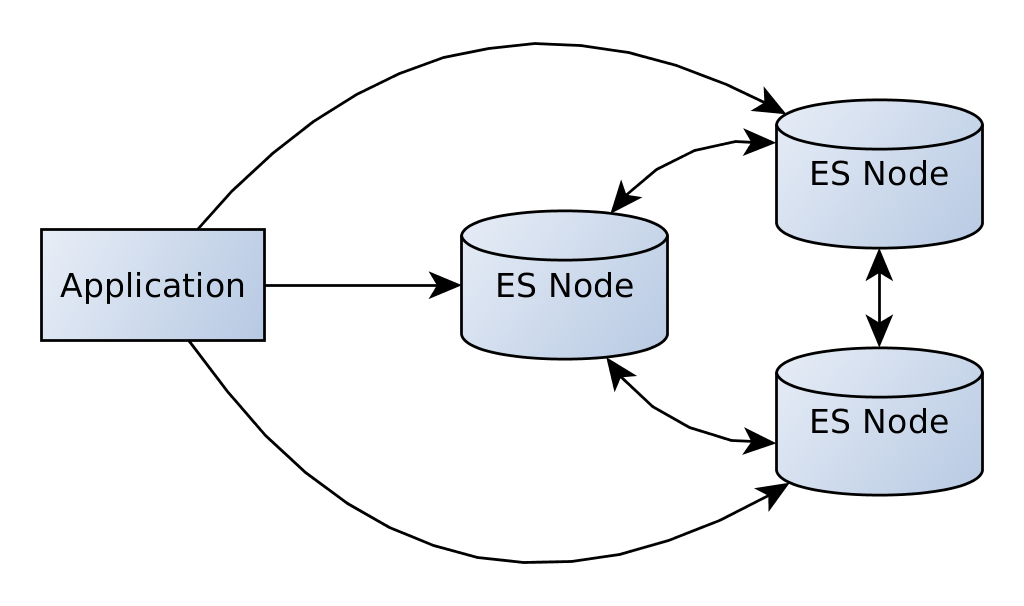
Now when one of the nodes goes down, we can still access the data using the other nodes. The feature can be enabled by setting client.transport.sniff to true when creating the client.
TransportAddress address =
new InetSocketTransportAddress(
InetAddress.getByName("localhost"), 9300);
Settings settings = Settings.builder()
.put("client.transport.sniff", true)
.build();
Client client = new PreBuiltTransportClient(settings)
addTransportAddress(address);
This feature works by requesting the current state of the cluster from the known node using one of the management APIs of elasticsearch. When configured this is done during startup and in an regular interval, by default every 5s.
Sniffing is an important feature to make sure your application stay up even during node failure.
When using the Transport Client you have some obvious benefits: As the client is shipped with the server (and even includes a dependency to the server) you can be sure that all of the current API is available for use in your client code. Communication is more efficient than JSON over HTTP and there is support for client side load balancing.
On the other side there are some drawbacks as well: As the transport protocol is an internal protocol you need to use a compatible elasticsearch version on the server and the client. Also, rather unexpected, this also means that a similar JDK version needs to be used. Additionally you need to include all of the dependencies to elasticsearch in your application. This can be a huge problem, especially with larger existing applications. For example it might happen that a CMS already ships some version of Lucene. Often it is not possible to resolve dependency conflicts like this.
Fortunately, there is a solution for this.
RestClient
elasticsearch 5.0 introduced a new client that uses the HTTP API of elasticsearch instead of the internal protocol. This requires far less dependencies. Also you don't need to care about the version that much - the current client can be used with elasticsearch 2.x as well.
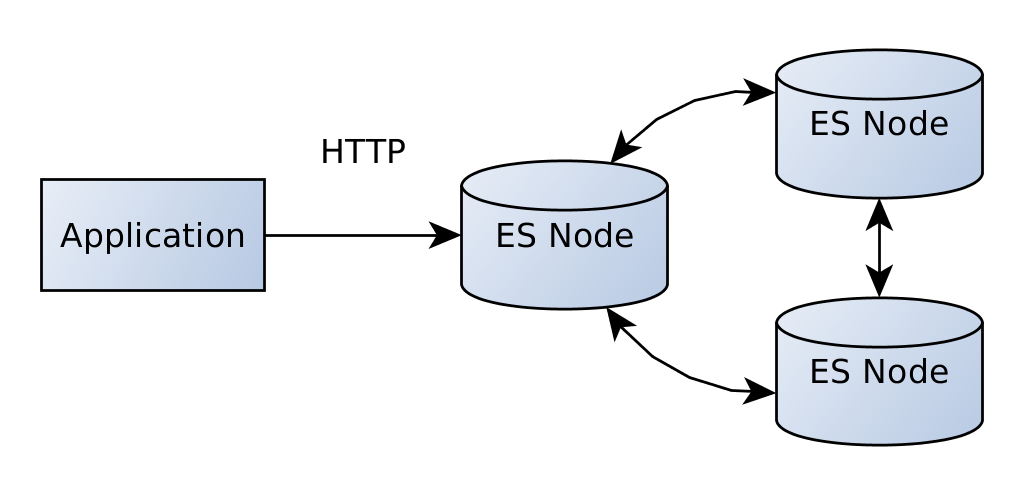
But there is also a drawback - it doesn't have a lot of features yet.
The client is available as a Maven artifact as well.
dependencies {
compile group: 'org.elasticsearch.client',
name: 'rest',
version: '5.0.0'
}
The client only depends on the apache httpclient and its dependencies. This is a Gradle listing of all the dependencies.
+--- org.apache.httpcomponents:httpclient:4.5.2
+--- org.apache.httpcomponents:httpcore:4.4.5
+--- org.apache.httpcomponents:httpasyncclient:4.1.2
+--- org.apache.httpcomponents:httpcore-nio:4.4.5
+--- commons-codec:commons-codec:1.10
\--- commons-logging:commons-logging:1.1.3
It can be instanciated by passing in one or more HttpHost.
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http"))
.build();
As there is not a lot of functionality as of now most of the JSON is just available as a String. This is an example of executing a match_all query and transform the response to a String using a helper method.
HttpEntity entity = new NStringEntity(
"{ \"query\": { \"match_all\": {}}}",
ContentType.APPLICATION_JSON);
// alternative: performRequestAsync
Response response = restClient.performRequest("POST", "/_search", emptyMap(), entity);
String json = toString(response.getEntity());
// ...
Indexing data is low level as well. You just send the String containing the JSON document to the endpoint. The client supports sniffing using a separate library. Besides the fact that there are less dependencies and the elasticsearch version is not as important anymore there is another benefit for operations: The cluster can now be separated from the applications with HTTP being the only protocol to talk to the cluster.
Most of the functionality depends on the Apache http client directly. There is support for setting timeouts, using basic auth, custom headers and error handling.
For now there is no query support. If you are able to add the elasticsearch dependency to your application (which of course voids some of the benefits again) you can use the SearchSourceBuilder and related functionality to create Strings for the query.
Besides the new RestClient there is also another HTTP client available that has more features: The community built client Jest.
Jest
Jest is available for a long time already and is a viable alternative to the standard clients. It is available via Maven central as well.
dependencies {
compile group: 'io.searchbox',
name: 'jest',
version: '2.0.0'
}
The JestClient is the central interface that allows to send requests to elasticsearch. It can be created using a factory.
JestClientFactory factory = new JestClientFactory();
factory.setHttpClientConfig(new HttpClientConfig
.Builder("http://localhost:9200")
.multiThreaded(true)
.build());
JestClient client = factory.getObject();
As with the RestClient Jest doesn't have any support for generating queries. You can either create them using String templating or reuse the elasticsearch builders (with the drawback of having to manage all dependencies again).
A builder can be used to create the search request.
String query = jsonStringThatMagicallyAppears;
Search search = new Search.Builder(query)
.addIndex("library")
.build();
SearchResult result = client.execute(search);
assertEquals(Integer.valueOf(1), result.getTotal());
The result can be processed by traversing the Gson object structure which can become rather complex.
JsonObject jsonObject = result.getJsonObject();
JsonObject hitsObj = jsonObject.getAsJsonObject("hits");
JsonArray hits = hitsObj.getAsJsonArray("hits");
JsonObject hit = hits.get(0).getAsJsonObject();
// ... more boring code
But that is not how you normally work with Jest. The good thing about Jest is that it directly supports indexing and search Java beans. For example we can have a representation of our dish documents.
public class Dish {
private String food;
private List<String> tags;
private Favorite favorite;
@JestId
private String id;
// ... getters and setters
}
This class can then be automatically populated from the search result.
Dish dish = result.getFirstHit(Dish.class).source;
assertEquals("Roti Prata", dish.getFood());
Of course the bean support can be used to index data as well.
Jest can be a good alternative when accessing elasticsearch via http. It has a lot of useful functionality like the bean support when indexing and searching and a sniffing feature called node discovery. Unfortunately you have to create the search queries yourself but this is the case for the RestClient as well.
Now that we have looked at three clients it is time to see an abstraction on a higher level.
Spring Data Elasticsearch
The family of Spring Data projects provides access to different data stores using a common programming model. It doesn't try to provide an abstraction over all stores, the specialities of each store are still available. The most impressive feature is the dynamic repositories that allow you to define queries using an interface. Popular modules are Spring Data JPA for accessing relational databases and Spring Data MongoDB.
Like all Spring modules the artifacts are available in Maven central.
dependencies {
compile group: 'org.springframework.data',
name: 'spring-data-elasticsearch',
version: '2.0.4.RELEASE'
}
The documents to be indexed are represented as Java beans using custom annotations.
@Document(indexName = "spring_dish")
public class Dish {
@Id
private String id;
private String food;
private List<String> tags;
private Favorite favorite;
// more code
}
Different annotations can be used to define how the document will be stored in elasticsearch. In this case we just define the index name to use when persisting the document and the property that is used for storing the id generated by elasticsearch.
For accessing the documents one can define an interface typed to the dish class. There are different interfaces available for extension, ElasticsearchCrudRepository provides generic index and search operations.
public interface DishRepository
extends ElasticsearchCrudRepository<Dish, String> {
}
The module provides a namespace for XML configuration.
<elasticsearch:transport-client id="client" />
<bean name="elasticsearchTemplate"
class="o.s.d.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="client"/>
</bean>
<elasticsearch:repositories
base-package="de.fhopf.elasticsearch.springdata" />
The transport-client element instanciates a transport client, ElasticsearchTemplate provides the common operations on elasticsearch. Finally, the repositories element instructs Spring Data to scan for interfaces extending one of the Spring Data interface. It will automatically create instances for those.
You can then have the repository wired in your application and use it for storing and finding instances of Dish.
Dish mie = new Dish();
mie.setId("hokkien-prawn-mie");
mie.setFood("Hokkien Prawn Mie");
mie.setTags(Arrays.asList("noodles", "prawn"));
repository.save(Arrays.asList(hokkienPrawnMie));
// one line ommited
Iterable<Dish> dishes = repository.findAll();
Dish dish = repository.findOne("hokkien-prawn-mie");
Retrieving documents by id is not very interesting for a search engine. To really query documents you can add more methods to your interface that follow a certain naming convention.
public interface DishRepository
extends ElasticsearchCrudRepository<Dish, String> {
List<Dish> findByFood(String food);
List<Dish> findByTagsAndFavoriteLocation(String tag, String location);
List<Dish> findByFavoritePriceLessThan(Double price);
@Query("{\"query\": {\"match_all\": {}}}")
List<Dish> customFindAll();
}
Most of the methods start with findBy followed by one or more properties. For example findByFood will query the field food with the given parameter. Structured queries are possible as well, in this case by adding lessThan. This will return all dishes that have a lower price than the given one. The last method uses a different approach. It doesn't follow a naming convention but uses a Query annotation instead. Of course this query can contain placeholders for parameters as well.
To wrap up, Spring Data Elasticsearch is an interesting abstraction on top of the standard client. It is somewhat tied to a certain elasticsearch version, the current release uses version 2.2. There are plans for making it compatible with 5.x but this may still take some time. There is a pull request that uses Jest for communication but it is unclear if and when this will be merged. Unfortunately there is not a lot activity in the project.
Conclusion
We have looked at three Java clients and the higher level abstraction Spring Data Elasticsearch. Each of those has its pros and cons and there is no advice to use one in all cases. The transport client has full API support but is tied to the elasticsearch dependency. The RestClient is the future and will one day supersede the transport client. Feature wise it is currently very low level. Jest has a richer API but is developed externally and the company behind it doesn't seem to exist anymore though there is activity by the commiters in the project. Spring Data Elasticsearch on the other hand is better suited for developers using Spring Data already and don't want to get in contact with the elasticsearch API directly. It is currently tied to a version of the standard client, development activity is rather low.