
Elasticsearch is Distributed by Default
07 Feb 2014One of the big advantages Elasticsearch has over Solr is that it is really easy to get started with. You can download it, start it, index and search immediately. Schema discovery and the JSON based REST API all make it a very beginner friendly tool.
Also, another aspect, Elasticsearch is distributed by default. You can add nodes that will automatically be discovered and your index can be distributed across several nodes.
The distributed nature is great to get started with but you need to be aware that there are some consequences. Distribution comes with a cost. In this post I will show you how relevancy of search results might be affected by sharding in Elasticsearch.
Relevancy
As Elasticsearch is based on Lucene it also uses its relevancy algorithm by default, called TF/IDF. Term frequency (the amount of terms in a document) and the frequency of the term in an index (IDF) are important parts of the relevancy function. You can see details of the default formula in the Lucene API docs but for this post it is sufficient to know that the more often a term occurs in a document the more relevant it is considered. Terms that are more frequent in the index are considered less relevant.
A Problematic Example
Let's see the problem in action. We are starting with a fresh Elasticsearch instance and index some test documents. The documents only consist of one field that has the same text in it:
curl -XPOST http://localhost:9200/testindex/doc/0 -d '{ "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }'
{"ok":true,"_index":"testindex","_type":"doc","_id":"0","_version":1}
curl -XPOST http://localhost:9200/testindex/doc/1 -d '{ "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }'
{"ok":true,"_index":"testindex","_type":"doc","_id":"1","_version":1}
curl -XPOST http://localhost:9200/testindex/doc/2 -d '{ "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }'
{"ok":true,"_index":"testindex","_type":"doc","_id":"2","_version":1}
curl -XPOST http://localhost:9200/testindex/doc/3 -d '{ "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }'
{"ok":true,"_index":"testindex","_type":"doc","_id":"3","_version":1}
curl -XPOST http://localhost:9200/testindex/doc/4 -d '{ "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }'
{"ok":true,"_index":"testindex","_type":"doc","_id":"4","_version":1}When we search for those documents by text they of course are returned correctly.
curl -XGET "http://localhost:9200/testindex/doc/_search?q=title:hut&pretty=true"
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.10848885,
"hits" : [ {
"_index" : "testindex",
"_type" : "doc",
"_id" : "4",
"_score" : 0.10848885, "_source" : { "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }
}, {
"_index" : "testindex",
"_type" : "doc",
"_id" : "0",
"_score" : 0.10848885, "_source" : { "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }
}, {
"_index" : "testindex",
"_type" : "doc",
"_id" : "1",
"_score" : 0.10848885, "_source" : { "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }
}, {
"_index" : "testindex",
"_type" : "doc",
"_id" : "2",
"_score" : 0.10848885, "_source" : { "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }
}, {
"_index" : "testindex",
"_type" : "doc",
"_id" : "3",
"_score" : 0.10848885, "_source" : { "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }
} ]
}
}Now, let's index five more documents that are similar to the first documents but contain our test term Hut only once.
curl -XPOST http://localhost:9200/testindex/doc/5 -d '{ "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat er nicht" }'
{"ok":true,"_index":"testindex","_type":"doc","_id":"5","_version":1}
curl -XPOST http://localhost:9200/testindex/doc/6 -d '{ "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat er nicht" }'
{"ok":true,"_index":"testindex","_type":"doc","_id":"6","_version":1}
curl -XPOST http://localhost:9200/testindex/doc/7 -d '{ "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat er nicht" }'
{"ok":true,"_index":"testindex","_type":"doc","_id":"7","_version":1}
curl -XPOST http://localhost:9200/testindex/doc/8 -d '{ "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat er nicht" }'
{"ok":true,"_index":"testindex","_type":"doc","_id":"8","_version":1}
curl -XPOST http://localhost:9200/testindex/doc/9 -d '{ "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat er nicht" }'
{"ok":true,"_index":"testindex","_type":"doc","_id":"9","_version":1}As the default relevancy formula takes the term frequency in a document into account those documents should score less than our original documents. So if we query for hut again the results still contain our original documents at the beginning:
curl -XGET "http://localhost:9200/testindex/doc/_search?q=title:hut&pretty=true"
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 10,
"max_score" : 0.2101998,
"hits" : [ {
"_index" : "testindex",
"_type" : "doc",
"_id" : "4",
"_score" : 0.2101998, "_source" : { "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }
}, {
[...]
}, {
"_index" : "testindex",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2101998, "_source" : { "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }
}, {
"_index" : "testindex",
"_type" : "doc",
"_id" : "9",
"_score" : 0.1486337, "_source" : { "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat er nicht" }
}, {
[...]
}, {
"_index" : "testindex",
"_type" : "doc",
"_id" : "8",
"_score" : 0.1486337, "_source" : { "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat er nicht" }
} ]
}
}We are still happy. The most relevant documents are at the top of our search results. Now let's index something that is completely different from our original documents:
curl -XPOST http://localhost:9200/testindex/doc/10 -d '{ "title" : "mayhem and chaos" }'
{"ok":true,"_index":"testindex","_type":"doc","_id":"10","_version":1}Now, if we search again for our test term something strange will happen:
curl -XGET "http://localhost:9200/testindex/doc/_search?q=title:hut&pretty=true"
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 10,
"max_score" : 0.35355338,
"hits" : [ {
"_index" : "testindex",
"_type" : "doc",
"_id" : "3",
"_score" : 0.35355338, "_source" : { "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }
}, {
"_index" : "testindex",
"_type" : "doc",
"_id" : "8",
"_score" : 0.25, "_source" : { "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat er nicht" }
}, {
"_index" : "testindex",
"_type" : "doc",
"_id" : "4",
"_score" : 0.2101998, "_source" : { "title" : "Mein Hut der hat vier Ecken, 4 Ecken hat mein Hut" }
}, {
[...]
} ]
}
}Though the document we indexed last has nothing to do with our original documents it influenced our search and one of the documents that should score less is now the second result. This is something that you wouldn't expect. The behavior is caused by the default sharding of Elasticsearch that distributes a logical Elasticsearch index across several Lucene indices.
Sharding
When you are starting a single instance and index some documents Elasticsearch will by default create five shards under the hood, so there are five Lucene indices. Each of those shards contains some of the documents you are adding to the index. The assignment of documents to a shard happens in a way so that the documents will be distributed evenly.
You can get information about the shards and their document counts using the indices status API or more visually appealing using one of the plugins, e.g. elasticsearch-head. There are five shards for our index, once we click on a shard we can see further details about the shard, including the doc count.
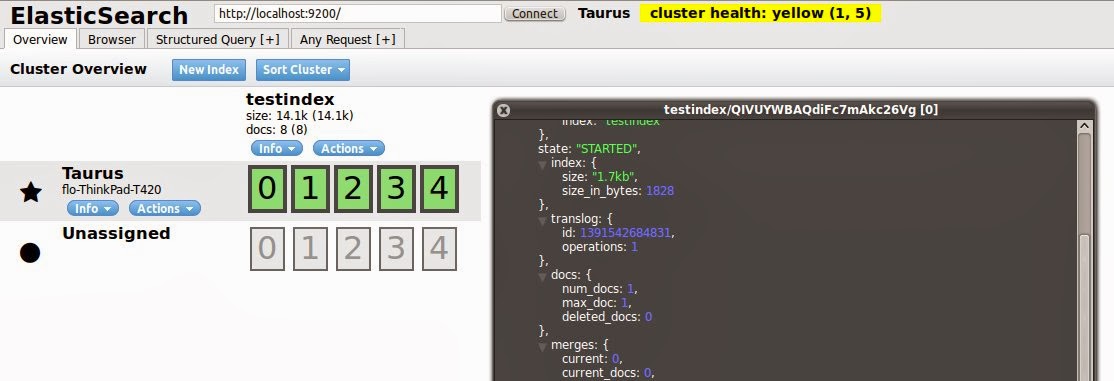
If you check the shards right after you indexed the first five documents you will notice that those are distributed evenly across all shards. Each shard contains one of the documents. The second batch is again distributed evenly. The final document we index creates some imbalance. One shard will have an additional document.
The Effects on Relevancy
Each shard in Elasticsearch is a Lucene index in itself and as an index in Elasticsearch consists of multiple shards it needs to distribute the queries across multiple Lucene indices. Especially the inverse document frequency is difficult to calculate in this case.
Reconsider the Lucene relevancy formula: the term frequency as well as the inverse document frequency are important. When indexing the original 5 documents all documents had the same term frequency as well as the same idf for our term. The next documents still had no impact on the idf as each document in the index still contained the term.
Now, when indexing the last document something potentially unexpected is happening. The new document is added to one of the shards. On this shard we therefore changed the inverse document frequency which is calculated from all the documents that contain the term but also takes the overall document count in the Lucene index into account. On the shard that contains the new document we increased the idf value as now there are more documents in the Lucene index. As idf has quite some weight on the overall relevancy score we "boosted" the documents of the Lucene index that now contains more documents.
If you'd like to see details on the relevancy calculation you can use the explain API or simply add a parameter explain=true. This will not only tell you all the details of the results of the relevancy function for each document but also which shard a document resides on. It can give you really useful information when debugging relevancy problems.
How to Fix It?
When beginning with Elasticsearch you might fix this by setting the your index to use one shard only. Though this will work it is not a good idea: Sharding is a very powerful feature of Elasticsearch and you shouldn't give it up on it easily. If you notice that there are problems with your relevancy that are caused by these issues you should rather try to use the search_type dfs_query_then_fetch instead of the default query_then_fetch. The difference between those is that dfs queries all the document frequencies of the shards in advance. This way Elasticsearch can calculate the overall document frequency and all results will be in the correct order:
curl -XGET "http://localhost:9200/testindex/doc/_search?q=title:hut&pretty=true&explain=true&search_type=dfs_query_then_fetch"Conclusion
Though the example we have seen here is artificially constructed this is something that can occur and I have already seen in live applications. The behaviour can especially be relevant when there are either very few documents or your documents are distributed to the shards in an unfortunate way. It is great that Elasticsearch makes distributed searches as easy and as performant as possible but you need to be aware that you might not get exact hits.
Zachary Thong has written a blog post about this behavior as well at the Elasticsearch blog.