
Cope with Failure - Actor Supervision in Akka
11 Oct 2013A while ago I showed an example on how to use Akka to scale a simple application with multiple threads. Tasks can be split into several actors that communicate via immutable messages. State is encapsulated and each actor can be scaled independently. While implementing an actor you don't have to take care of low level building blocks like Threads and synchronization so it is far more easy to reason about the application.
Besides these obvious benefits, fault tolerance is another important aspect. In this post I'd like to show you how you can leverage some of Akkas characteristics to make our example more robust.
The Application
To recap, we are building a simple web site crawler in Java to index pages in Lucene. The full code of the examples is available on GitHub. We are using three actors: one which carries the information on the pages to be visited and visited already, one that downloads and parses the pages and one that indexes the pages in Lucene.
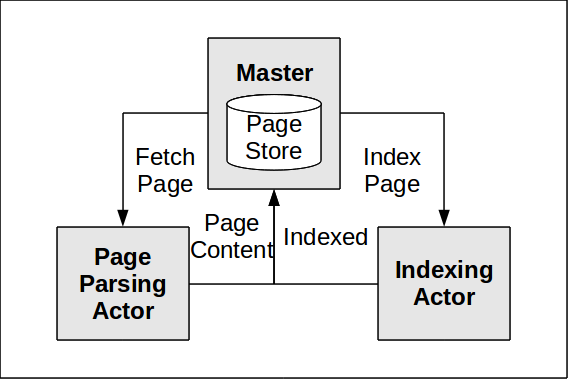
By using several actors to download and parse pages we could see some good performance improvements.
What could possibly go wrong?
Things will fail. We are relying on external services (the page we are crawling) and therefore the network. Requests could time out or our parser could choke on the input. To make our example somewhat reproducible I just simulated an error. A new PageRetriever, the ChaosMonkeyPageRetriever sometimes just throws an Exception:
@Override
public PageContent fetchPageContent(String url) {
// this error rate is derived from scientific measurements
if (System.currentTimeMillis() % 20 == 0) {
throw new RetrievalException("Something went horribly wrong when fetching the page.");
}
return super.fetchPageContent(url);
}You can surely imagine what happens when we use this retriever in the sequential example that doesn't use Akka or threads. As we didn't take care of the failure our application just stops when the Exception occurs. One way we could mitigate this is by surrounding statements with try/catch-Blocks but this will soon intermingle a lot of recovery and fault processing code with our application logic. Once we have an application that is running in multiple threads fault processing gets a lot harder. There is no easy way to notify other Threads or save the state of the failing thread.
Supervision
Let's see Akkas behavior in case of an error. I added some logging that indicates the current state of the visited pages.
1939 [default-akka.actor.default-dispatcher-5] INFO de.fhopf.akka.actor.Master - inProgress: 55, allPages: 60
1952 [default-akka.actor.default-dispatcher-4] INFO de.fhopf.akka.actor.Master - inProgress: 54, allPages: 60
[ERROR] [10/10/2013 06:47:39.752] [default-akka.actor.default-dispatcher-5] [akka://default/user/$a/$a] Something went horribly wrong when fetching the page.
de.fhopf.akka.RetrievalException: Something went horribly wrong when fetching the page.
at de.fhopf.akka.actor.parallel.ChaosMonkeyPageRetriever.fetchPageContent(ChaosMonkeyPageRetriever.java:21)
at de.fhopf.akka.actor.PageParsingActor.onReceive(PageParsingActor.java:26)
at akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:167)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:498)
at akka.actor.ActorCell.invoke(ActorCell.scala:456)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:237)
at akka.dispatch.Mailbox.run(Mailbox.scala:219)
at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:386)
at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
1998 [default-akka.actor.default-dispatcher-8] INFO de.fhopf.akka.actor.Master - inProgress: 53, allPages: 60
2001 [default-akka.actor.default-dispatcher-12] INFO de.fhopf.akka.actor.PageParsingActor - Restarting PageParsingActor because of class de.fhopf.akka.RetrievalException
2001 [default-akka.actor.default-dispatcher-2] INFO de.fhopf.akka.actor.PageParsingActor - Restarting PageParsingActor because of class de.fhopf.akka.RetrievalException
2001 [default-akka.actor.default-dispatcher-10] INFO de.fhopf.akka.actor.PageParsingActor - Restarting PageParsingActor because of class de.fhopf.akka.RetrievalException
[...]
2469 [default-akka.actor.default-dispatcher-12] INFO de.fhopf.akka.actor.Master - inProgress: 8, allPages: 78
2487 [default-akka.actor.default-dispatcher-7] INFO de.fhopf.akka.actor.Master - inProgress: 7, allPages: 78
2497 [default-akka.actor.default-dispatcher-5] INFO de.fhopf.akka.actor.Master - inProgress: 6, allPages: 78
2540 [default-akka.actor.default-dispatcher-13] INFO de.fhopf.akka.actor.Master - inProgress: 5, allPages: 78
We can see each exception that is happening in the log file but our application keeps running. That is because of Akkas supervision support. Actors form hierarchies where our PageParsingActor is a child of the Master actor because it is created from its context. The Master is responsible to determine the fault strategy for its children. By default it will restart the Actor in case of an exception which makes sure that the next message is processed correctly. This means even in case of an error Akka tries to keep the system in a running state.
The reaction to a failure is determined by the method supervisorStrategy() in the parent actor. Based on an Exception class you can choose several outcomes:
- resume: Keep the actor running as if nothing had happened
- restart: Replace the failing actor with a new instance
- suspend: Stop the failing actor
- escalate: Let your own parent decide on what to do
A supervisor that would restart the actor for our exception and escalate otherwise could be added like this:
// allow 100 restarts in 1 minute ... this is a lot but we the chaos monkey is rather busy
private SupervisorStrategy supervisorStrategy = new OneForOneStrategy(100, Duration.create("1 minute"), new Function() {
@Override
public Directive apply(Throwable t) throws Exception {
if (t instanceof RetrievalException) {
return SupervisorStrategy.restart();
}
// it would be best to model the default behaviour in other cases
return SupervisorStrategy.escalate();
}
});
@Override
public SupervisorStrategy supervisorStrategy() {
return supervisorStrategy;
} Let's come back to our example. Though Akka takes care of restarting our failing actors the end result doesn't look good. The application continues to run after several exceptions but our application then just stops and hangs. This is caused by our business logic. The Master actor keeps all pages to visit in the VisitedPageStore and only commits the Lucene index when all pages are visited. As we had several failures we didn't receive the result for those pages and the Master still waits.
One way to fix this is to resend the message once the actor is restarted. Each Actor class can implement some methods that hook into the actors lifecycle. In preRestart() we can just send the message again.
@Override
public void preRestart(Throwable reason, Option<Object> message) throws Exception {
logger.info("Restarting PageParsingActor and resending message '{}'", message);
if (message.nonEmpty()) {
getSelf().forward(message.get(), getContext());
}
super.preRestart(reason, message);
}Now if we run this example we can see our actors recover from the failure. Though some exceptions are happening all pages get visited eventually and everything will be indexed and commited in Lucene.
Though resending seems to be the solution to our failures you need to be careful to not break your system with it: For some applications the message might be the cause for the failure and by resending it you will keep your system busy with it in a livelock state. When using this approach you should at least add a count to the message that you can increment on restart. Once it is sent too often you can then escalate the failure to have it handled in a different way.
Conclusion
We have only handled one certain type of failure but you can already see how powerful Akka can be when it comes to fault tolerance. Recovery code is completely separated from the business code. To learn more on different aspects of error handling read the Akka documentation on supervision and fault tolerance or this excellent article by Daniel Westheide.